About Coinweb Sharding
This document refers to external research in order to position Coinweb sharding in relation to existing work.
In relation to the Ethereum Sharding FAQ and related Ethereum research
These concepts are from the (now old) phase 1 design for Ethereum sharding:
The Ethereum project has investigated proposer, collator, notary, and executor concepts where:
-
Proposers: A proposer is responsible for preparing the data that goes in a given shard. It prioritises so-called blobs (think, transactions) and assembles them into collations (think, blocks). Collations are proposed to collators for inclusion in the collation tree via an open auction amongst proposers. To prioritise blobs and maximise revenue proposers are expected to run executing nodes.
-
Collators: A collator is responsible for extending the head of the canonical chain of shards. It adjudicates on the availability of collation bodies and selects the highest-paying available collations from proposers. Collators are not required to run executing nodes. This allows for fast shuffling of the collator pool across shards, a key part of phase 1 sharding’s security.
-
Executors: An executor is responsible for running the enshrined execution engine on the canonical chain of a given shard, and posting crypto economic claims on state roots. This allows light-clients to guess the state root of a shard without running executing nodes. Executors are planned for phase 3 after an EVM state transition function is specified in phase 2.
They further define proposer + collator as.. prolators!
If we squint a bit, we can see L1 miners as collators for L2 transactions, while dsBrokers are proposers.
If we look at Coinweb sharding in this view, we can map some questions regarding this type of sharding design to Coinweb and see how it falls out.
Collators have no knowledge of state in Coinweb (and it's not needed)
In "Separating proposing and confirmation ofcollations", Buterin argues that "the nodes participating in the transaction ordering process still need to have access to the state, and still need to perform state executions, because they need to know whether or not the transactions they accept will pay for gas."
This does not hold for Coinweb, as the L1 "gas" (the miner fee for example) is unrelated to the L2 fee. The collator gets paid (at the L1 level) without having to care about whether the transaction makes sense or not. L1 gets paid for consensus and availability (and storage). The collation process is completely independent from state execution.
Now this creates complexity - you now need to pay both L1 "gas" as well as L2 fee. This is where dsBrokers step in as an intermediary that will let you buy L1 "gas" using L2 tokens.
This is repeated in the Sharding FAQ.
Congelated shard gas is solved by market mechanisms and dsBroker
The Ethereum sharding system introduces "congealed shard gas" as a mechanism to ensure stable gas prices across shards.
In Coinweb, this is problem is solved by the dsBroker which using normal market mechanisms will sell cross-chain transaction "collation services" at fixed L2 prices. Of course the dsBroker will sell this at a profit similar to an insurance company or financial broker.
Dangerous cascading reorganizations have been studied
In "Delayed state execution, finality and cross-chain operations", Buterin argues that:
We could simply have the reorg on shard A trigger a reorg on shard B, but that would be dangerous as it would be a DoS vulnerability: a small number of attackers reorging shard A could conceivably reorg every shard, if there is much cross-shard communication going on. The “dependency cone” of A will likely grow quickly. To prevent this, we can only go for the dumb solution: wait for the receipt on shard A to finalize, so that reorgs are simply not possible.
But separating state execution gives us another way out: if shard A does a reorg, then we don’t reorg any transactions on shard B, but rather we simply let the executors recalculate the state roots. Any operations on shard B that actually do depend on activity on shard A would have their consequences reorg’ed, but any operation on shard B that is not part of the dependency cone of the receipt would be left alone. Furthermore, it should be possible to calculate ahead of time that some operation on shard B is not part of the dependency cone of something in shard A simply by looking at the access lists of transactions (the access lists would be extended so that transactions can also access historical receipts on other shards), and so users would have private knowledge that their operation on shard B is safe and sound without waiting for confirmation from the global state root. With this kind of approach, we could allow cross-shard transactions to happen very quickly, possibly even allowing transactions to reference receipts from the most recent collation in some other shard.
The above is true, but to clarify how we describe this situation, we separate L1 and L2 reorganizations in Coinweb. In Coinweb, L1/L2 chains have neighbor chains, and cross-chain messages can only happen between neighbors. As L1 chains have no knowledge of L2 reorganizations and thus "collation" is not affected by this, the "dangerous DoS attack" described by Buterin will not happen at the L1 level (as described above).
However, how about the L2 level? As noted by Buterin above, re-calculating state can be done quickly in this case, but Coinweb also reduces the attack surface in this case by using neighbor chains, and thus while an attack on an L1 chain can happen, the attacker cannot send cross-chain messages to all other chains.
This issue and how to construct the communication graph between shards has also been studied in the Chainweb paper.
Re-calculating state is also much faster in Coinweb as calculating the state for a block is inherently parallel. It's fully task-parallel as each transaction is isolated, and data-parallel within a transaction.
Coinweb does heterogeneous sharding, but more, and better
The Ethereum Sharding FAQ is positive to hetregeneous sharding (here, here), where different shards will have different configurations of Casper CBC. Coinweb is a superset of this as it runs across any consensus protocol used by the L1 layer. We agree that heterogeneous sharding is very useful, such as having cheap centralized high-throughput computation as well as decentralized low-throughput computations in the same system.
However, Coinweb transactions can be secured by the full investment in mining equipment and consensus approaches by the whole market, not just a subset of the market. That is unobtainable for any chain-specific proposal. This includes any merge-mining based proposal as they rely on miner adoption.
Coinweb shards state, unlike, say Zilliqa
Coinweb transaction processing is fully parallel, and the trade-off we have is that synchronization happens between blocks and through cross-chain messages, only.
This is required to scale to the millions of transactions per second range. In a nutshell, there are no highly scalable systems that are not designed like this. Coinweb transaction processing can be seen as similar to GPU processing with rendering passes exchanged for blocks, or as map-reduce processing pipelines where block transactions act like mappers and there is an implicit shuffle and aggregation step between each block.
We believe unrestricted synchronous processing on shared state is a disaster for scalability (as seen in Ethereum for example).
Data availability is considered an unsolved problem, how does Coinweb address it?
In a sharded blockchain, data availability is considered a difficult problem to solve. For example, if one shard it controlled by malicious actors, then they could collude to withhold blocks, making it difficult/impossible for a fisherman, as in polkadot, to challenge invalid state calculations.
A neighbor graph like the one used in Coinweb seemingly has the same problem, just with the requirement that malicious actors need to control two shards (or chains in Coinweb). The malicious actors would control chains C and B, and attack chain A. They would withhold blocks from chain C, accept cross-chain transactions into chain B, while otherwise keeping it valid, and make chain A accept cross-chain transactions from chain B originating in a forged state from chain C.
Initially this is extremely hard to pull off in Coinweb for many reasons:
-
Evaluation of state in Coinweb is done in a parallel fashion. This also has the side-effect that it's possible to evaluate random subsets of the state of a block, so partial checks can be done cheaply.
-
Initial deployment of Coinweb will be done on L1 chains that are established in the marketplace with high market cap. Inhibiting availability of blocks on these chains requires taking control over the chain and will also be devastating for the L1 token.
It seems like Coinweb is quite heavy on computation. Is this an efficient chain?
The efficiency of the whole system should be considered. In order to analyze this, we need to look at computations that are required for security, and pure computations.
Assume there are three different networks of the same size that are used to do a certain computation, networks A, B, and C. An external observer wants to know the result of the computation. For network A (BFT), ⅔ of the nodes must be honest for the observer to get the correct result, for network B, 51% of the nodes(PoW), and for network C(RDoC), a single honest node is required.
If a node is randomly chosen to be honest with a given probability, obviously network C requires the least duplicated work, followed by B, and then A. C thus requires the least aggregated computational resources.
In the above case only networks A and B can implement consensus and do the computation entirely on their own. Network C requires access to an auxiliary network of type A or B that provides trusted broadcasts of messages. This is how Coinweb operates. A small part of the computation, the non-deterministic part, is done by the L1 layer. The deterministic part is done by the L2 layer.
Here it is important to note that all smart contracts are deterministic.
As mentioned above, Coinweb provides a separation between collation and execution, collation nodes are not required to perform the execution computation. With RDoC computation, the number of nodes necessary to provide execution computation is reduced to a few paid nodes. This leads to an order of magnitude less aggregated computation on Coinweb.
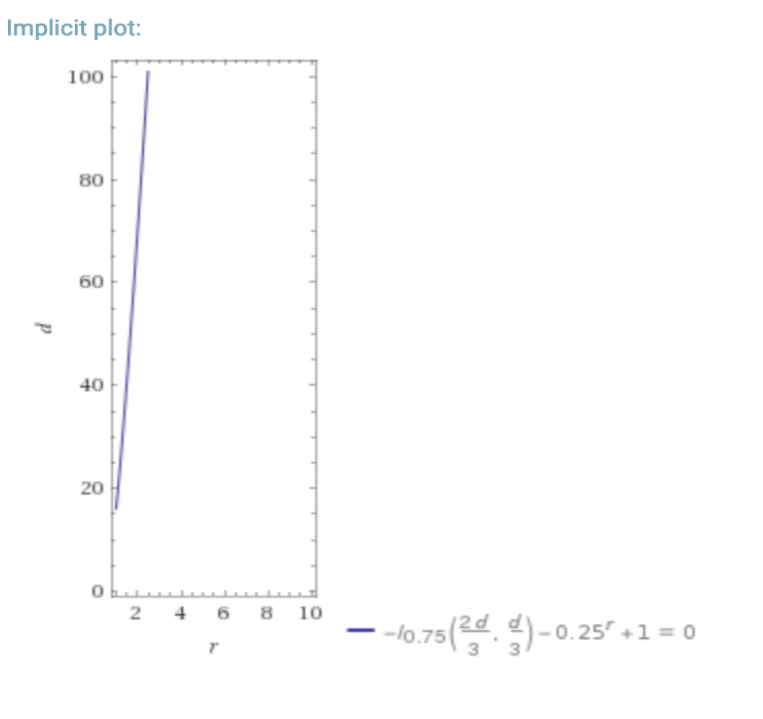
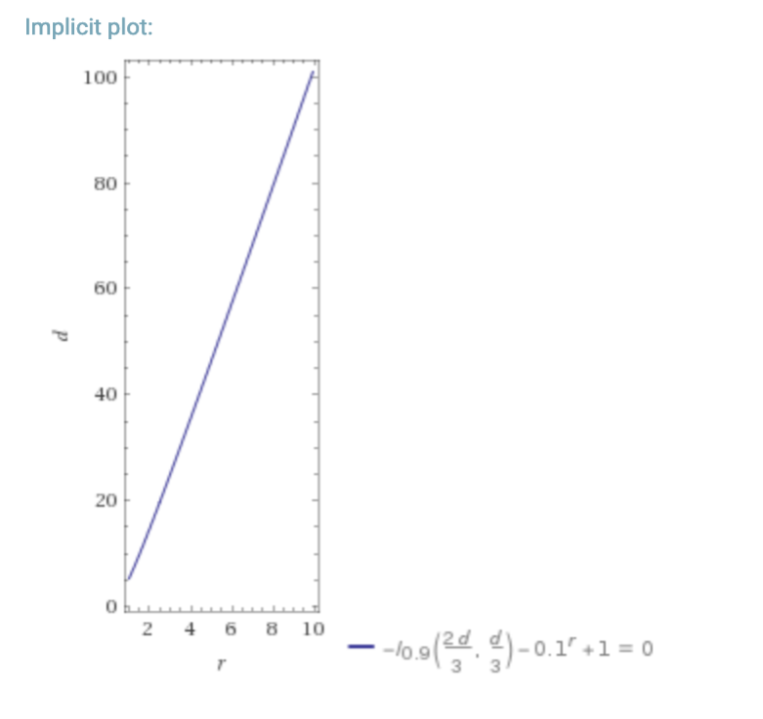
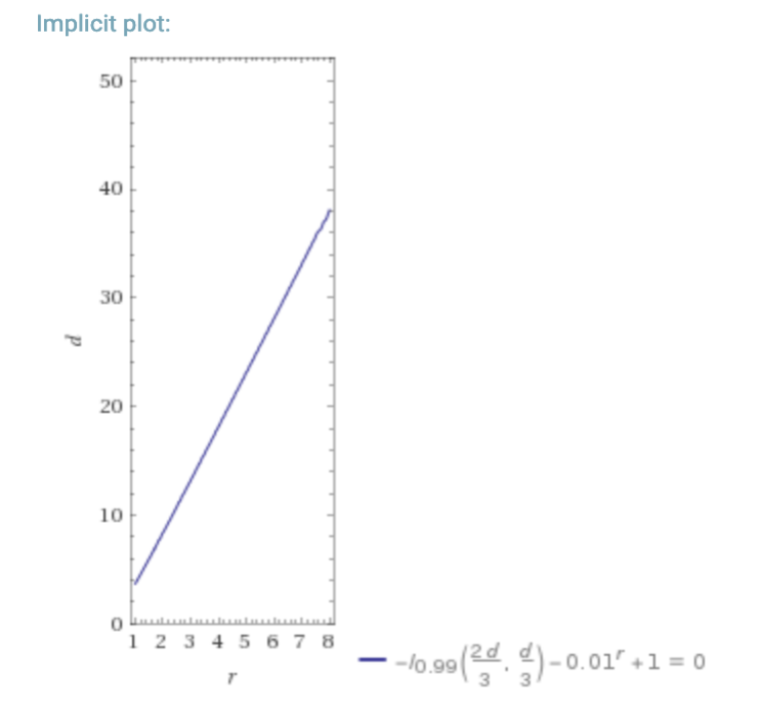
The following is a look at what happens if you have a dBFT/PoS requiring ⅔ honest nodes, vs RDoC. For a hypothetical “worst-case” where the probability of a participant/node being byzantine is 25% (lower % also for reference), we can look at the required number of nodes in a dBFT/PoS system, and an RDoC system for similar security.
| 25% probability of a node being evil | 10% probability of a node being evil |
|---|---|
 |
 |
| 1% probability of a node being evil | 0.1% probability of a node being evil |
|---|---|
 |
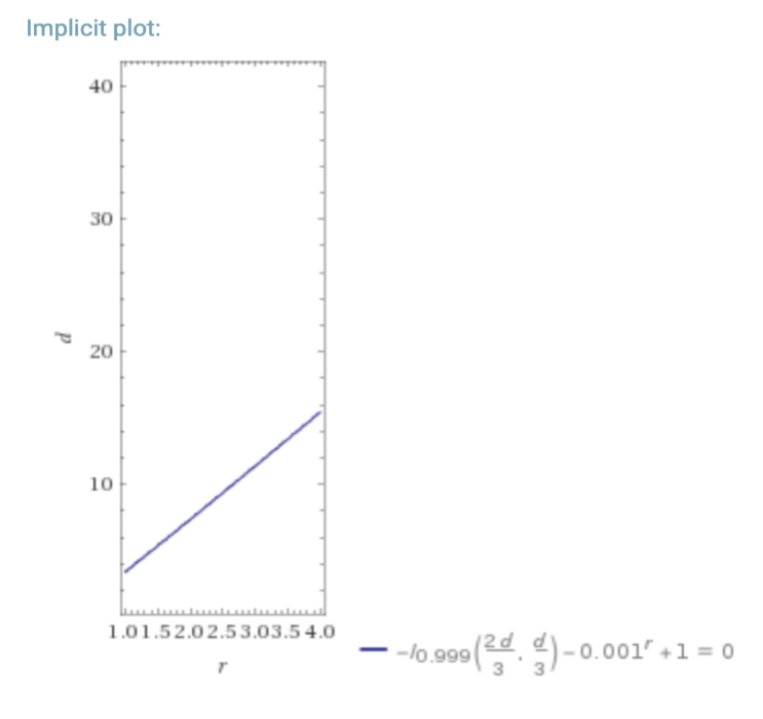 |
In the above graphs d = number of dBFT nodes, and r is the number of RDoC nodes. I is the regularized incomplete beta function, and I1-p( n-k, 1+k) is the CDF of the binomial distribution (probability of k honest nodes in n trials with probability p of a node being evil) which we use in this simple model.
This is a simplistic model, but assuming that the network needs to do some computation, it is clear that moving most of the computation into a separate layer that only requires a single honest computation saves massively on total aggregated compute resources, and thus enables scalability at the smart contract level.
How does L2 differ from a parachain?
The parachain idea is that we parallelize by creating multiple chains because each chain requires sequential evaluation.
This is not necessary, and not a good way to scale up. If we analyze collation and execution separately, collation can scale with global network bandwidth and topology, given the security constraints of the consensus algorithm. Execution, on the other hand, in the map-reduce model is inherently parallel and scales with local bandwidth and cpu. Running multiple chains to get equal efficiency as a map-reduce computational model is extremely expensive and wasteful. This is especially true when only a few contracts have most of the transactions.
A parachain artificially adds the complexity of computation as an artificial barrier to the scalability of a chain. However, there is no reason why a high-throughput chain can not be executed by a parallel computer, or be executed in a sharded manner.
We believe scaling is best handled at the architecture layer by cleanly separating collation and execution, and using parallel computation models.
In short:
Consensus is given by the L1 layer. L2 does not need its own consensus.
Parallelism in L2 is handled by the computation model and not tied to the L1 layer graph.
Communication in parallel execution is extremely cheap compared to intra-chain
Aggregated computation needed to drive the network is much lower as only one honest validator is needed.
Data is written into the L1 layer.
How does L2 differ from a sidechain?
Consensus is given by the L1 layer. L2 does not do its own consensus.
L2 is designed to communicate with multiple external chains.
You only need access to the main chain, not both the main chain and the sidechain.
Aggregated computation needed to drive the network is much lower as only one honest validator is needed.
Data is written into the L1 layer.